

De sectie Nederlands van de vakgroep Taalkunde van de Universiteit Gent staat sinds jaar en dag bekend voor de dialectologie. Alle professoren Nederlandse taalkunde waren tot voor kort dialectologen; de verzamelingen dialectologische gegevens die in de loop van bijna 100 jaar aangelegd zijn, zijn dan ook zeer uitgebreid en worden gaandeweg gedigitaliseerd om ze voor vakgenoten en het publiek beter te kunnen ontsluiten.
Een belangrijke collectie is de verzameling dialectbanden die in de loop van de jaren 60 en 70 van de vorige eeuw tot stand is gekomen op initiatief van de professoren Willem Pée en Valère Vanacker. Prof. Vanacker was een van de pioniers van de studie van de dialectsyntaxis, en voor die studie had hij het plan opgevat om van alle dialecten in Vlaanderen een goede bandopneming te (laten) maken van een zgn. ‘vrij gesprek’ met goede dialectinformanten. Die bandopnemingen zouden ook een belangrijke aanvulling kunnen betekenen bij het materiaal in de Reeks Nederlandse Dialektatlassen [2]. Het Dialectenbureau (nu ‘Meertensinstituut’) in Amsterdam was hem in de jaren 50 daarin voorgegaan voor de dialecten in Nederland, op initiatief van Jo Daan (zie Rensink 1962 en https://www.meertens.knaw.nl/soundbites/).
prof. dr. W.Pée
In 1962 werd aan prof. Pée door het Fonds voor Fundamenteel en Kollektief Onderzoek [3] een krediet toegekend waardoor het mogelijk werd gemaakt met de verzameling te beginnen [4]. De dialectsprekers moesten aan een aantal voorwaarden voldoen, zodat de onderzoeker er zeker van kon zijn met echt en onvervalst plaatselijk dialect te maken te hebben. De ideale zegsman of zegsvrouw was ter plaatse geboren en getogen, was honkvast en had een relatief hoge leeftijd en een lage opleidingsgraad. Ideaal was ook dat beide ouders en partner hetzelfde dialect spraken als de zegspersoon. In een dorp kwam men met zo’n profiel al snel bij de boerenbevolking terecht. Uiteraard moest de zegspersoon ook goed ter tale zijn en iets te vertellen hebben. Om ongewenste invloed van de standaardtaal te vermijden en de spontaneïteit van de gesprekssituatie te verhogen, werd het gesprek dikwijls gevoerd door een tussenpersoon die (ongeveer) hetzelfde dialect sprak als de informant. Alle opnames gebeurden bij de zegspersoon thuis, en duren gemiddeld zo’n half uur [5]. De meeste informanten zijn geboren rond 1900; de oudste zegsman is die voor het dorp Bossuit (geboren in 1871).
De informanten werden gezocht (en geïnterviewd) door het personeel van het Seminarie voor Vlaamse Dialectologie (voor een overzicht zie Vanacker en De Schutter 1967:39-40). Prof. Vanacker heeft ook geprobeerd zoveel mogelijk studenten te motiveren om in hun gemeente geschikte zegspersonen te vinden voor een opname. Aangezien de meeste Gentse studenten uit West- en Oost-Vlaanderen komen, zijn die twee provincies het beste bewerkt. Voor sommige gemeenten bestaat er meer dan één band; dat zijn dan meestal de plaatsen waarvoor een student als licentiaatsverhandeling een dialectsyntaxis heeft geschreven. Naarmate men naar het oosten gaat, worden de meetpunten helaas schaarser – vooral in Limburg (zie de kaart). Speciale aandacht is uitgegaan naar Frans-Vlaanderen, waar voor elk dorp een bandopneming is gemaakt. Voor sommige Frans-Vlaamse gemeenten zijn de Gentse bandopnemingen nu de enige getuigen van het Vlaams dat er eeuwenlang werd gesproken.
De biografische gegevens van de sprekers werden op technische fiches (A4-formaat) bijgehouden. Ze zijn nu alle ingescand en in de database verwerkt. Wel werden de familienamen van de informanten om redenen van privacy niet vrijgegeven. De belangrijkste gegevens i.v.m. de taal van de informanten zijn natuurlijk de data m.b.t. leeftijd, opleiding en honkvastheid. De inhoud van de gesprekken werd niet of erg onvolledig weergegeven – dialectologen zijn immers vooral in de vorm van de taal geïnteresseerd. De banden bevatten in elk geval zeer talrijke gegevens over het traditionele landbouwbedrijf.
De bandopnemingen zijn voor een deel toegankelijk gemaakt door transcripties. Die transcripties zijn niet fonetisch, maar ‘woordelijk’, d.w.z. dat de dialectische uitspraak in een vernederlandste vorm is weergegeven. De transcripties werden gemaakt door jobstudenten aan de hand van een aantal richtlijnen – die met wisselende ijver en kunde werden opgevolgd. De beste transcripties zijn die die voor een syntactische of fonologische licentiaatsverhandeling gediend hebben. Elke transcriptie kwam tot stand in drie stappen: eerst werd een geschreven tekst gemaakt, dan werd die gecorrigeerd en vervolgens uitgetikt.
De nieuwe, digitale transcripties worden aan de hand van een transcriptieprotocol gemaakt. Elke transcriptie bestaat uit twee lagen, één dichter bij het dialect en één dichter bij de standaardtaal. Er wordt niet met fonetische tekens getranscribeerd, maar er wordt vernederlandst. Vernederlandsen betekent niet vertalen naar het Nederlands, maar wel abstractie maken van dialectische fonologie, morfologie of syntaxis. Maatstaf voor de spelling is het Groene Boekje. Meer info via www.gcnd.ugent.be
2. Het digitaliseringsproject
In 2012 werd het project “Stemmen uit het verleden. Digitaliseren en ontsluiten van dialectopnames gemaakt in de jaren 60 en 70 door het Seminarie voor Nederlandse Taalkunde en Vlaamse Dialectologie’ door de UGent goedgekeurd. Het was een aanvulling op een grootschalig project dat in 2009 werd opgestart en dat een website over taalvariatie beoogde. We kregen ook aanvullende subsidies van de Vlaamse Gemeenschap en van de provincies Oost- en West-Vlaanderen en Limburg.
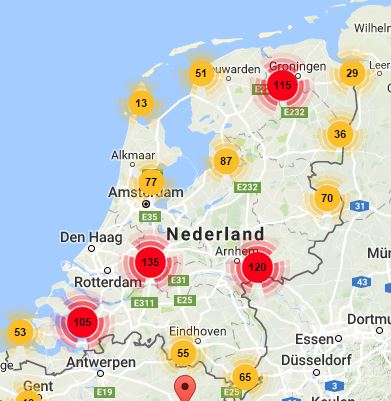
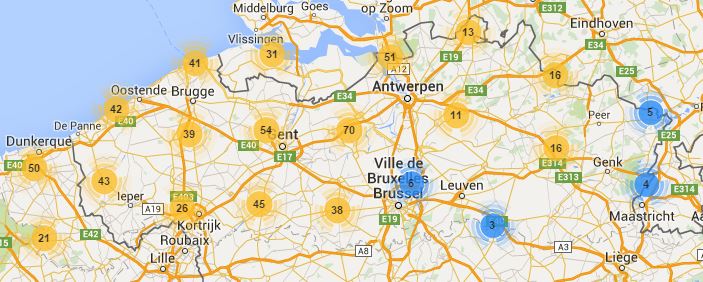
De digitalisering hield volgende zaken in. Allereerst werden de 783 geluidsbanden gedigitaliseerd. Een technisch medewerker van de toenmalige vakgroep Nederlandse Taalkunde, Rieke Willems, heeft ongeveer 500 banden op zeer professionele manier naar wav-bestanden omgezet. Toen mevr. Willems wegens een reorganisatie naar een andere sectie van de vakgroep werd gemuteerd, is de rest van de banden gedigitaliseerd door een gespecialiseerde firma. Er zijn voor 550 verschillende plaatsen opnames; voor sommige gemeenten is er meer dan één opname voorhanden. De verdeling per provincies / streek is als volgt: Frans-Vlaanderen: 113, West-Vlaanderen: 188, Oost-Vlaanderen: 285, Antwerpen: 85, Vlaams-Brabant: 47, Limburg: 29, Henegouwen: 5, Zeeland: 31.
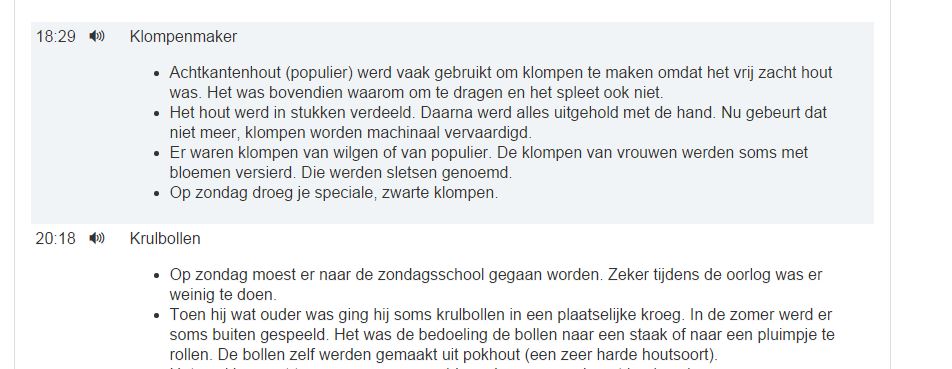
Op de tweede plaats werden alle metadata, d.i. alle biografische gegevens in verband met de zegslieden en technische gegevens over de banden, in een database ondergebracht. Op de derde plaats werden van de meeste banden korte inhouden gemaakt, zodat de inhoud van de banden ontsloten is. Die korte inhouden worden voorafgegaan door niet-gestandaardiseerde trefwoorden, waarop gezocht kan worden. Die korte inhouden zijn vooral voor de erfgoedsector en de mondelinge geschiedenis van belang. De bandenverzameling blijkt immers de grootste collectie levensverhalen te zijn van gewone volksmensen in de eerste helft van de vorige eeuw. Op de vierde plaats werden alle transcripties – voor zover aanwezig – ingescand en in de database ingevoerd; het zijn er 318 in totaal.
Verspreidingskaart van alle dialectopnames en originele transcripties
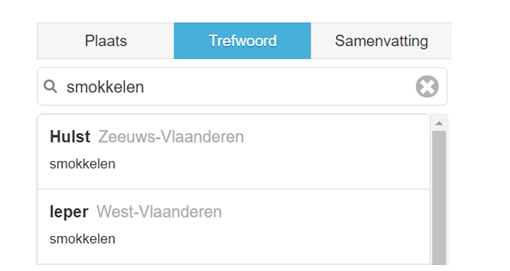
Ondertussen zijn er ook nieuwe, digitale transcripties gemaakt. Die transcripties zullen in de toekomst volledig doorzoekbaar zijn via het Instituut voor de Nederlandse Taal. Door die nieuwe, uniforme en kwalitatieve transcripties ligt de weg naar een systematische thematische ontsluiting open. De oude trefwoorden waren namelijk niet gestandaardiseerd en daarom was de thematische doorzoekbaarheid niet optimaal. Doordat bij de ene band bijvoorbeeld ‘Wereldoorlog I’ stond en bij de andere ‘Eerste Wereldoorlog’, was het lang niet evident de collectie efficiënt te doorzoeken. Er is daarom een gestandaardiseerde trefwoordthesaurus ontwikkeld, die hiërarchisch is opgebouwd en ook voorzien is van alternatieve termen. Gaandeweg worden de oude trefwoorden nu vervangen door nieuwe, gestandaardiseerde trefwoorden. Daarnaast noteren we nu ook tijdsindicaties bij de trefwoorden, zodat je meteen de relevante geluidspassage kunt vinden en beluisteren, en je dus niet door de hele opname moet. Voorlopig zijn er al 109 opnames thematisch doorzoekbaar aan de hand van de gestandaardiseerde trefwoorden. De andere opnames zullen in de toekomst onder handen genomen worden, maar in de tussentijd zijn ook die opnames thematisch doorzoekbaar aan de hand van de oude, niet-gestandaardiseerde trefwoorden.
3. Wensen voor de toekomst
De bandenverzameling is indrukwekkend, maar helaas niet volledig. Ideaal zou zijn dat er voor elk plaatselijk dialect in Vlaanderen een goede bandopneming zou bestaan – met een goede samenvatting van de inhoud ervan. Er is nog heel wat te doen voor de provincies Antwerpen, Vlaams-Brabant en vooral Limburg. De dialectsprekers die aan de criteria voor de verzameling voldoen, zijn stilaan aan het uitsterven. Om de traditionele dialecten vast te leggen heeft men immers zegspersonen nodig die vόόr de jaren 60 van de vorige eeuw gesocialiseerd zijn, d.i. met een traditioneel dialect als moedertaal volwassen zijn geworden. Enkel personen die vόόr 1940 zijn geboren, hebben hun taal nog geleerd vόόr de democratisering van het onderwijs en de introductie van de mass media, die de Nederlandse standaardtaal naar alle lagen van de bevolking hebben gebracht. Er rest dus nog maar weinig tijd om de verzameling te vervolledigen.
De verzameling is gedeeltelijk ontsloten met transcripties, die in handschrift of in typoscript beschikbaar zijn. Een belangrijke wens voor de toekomst is het ontsluiten van de hele verzameling door goede transcripties die op een eenvormige wijze tot stand zijn gebracht. Er is daarvoor een transcriptieprotocol ontwikkeld en momenteel zijn er verschillende jobstudenten en vrijwilligers digitale transcripties aan het maken van de volledige collectie.
Die transcripties vormen de basis voor een digitaal corpus, het Gesproken Corpus van de zuidelijk-Nederlandse Dialecten (GCND), zodat ze doorzoekbaar zijn en voor wetenschappelijk onderzoek ter beschikking kunnen komen. Een dialectband transcriberen is een tijdrovend werk; een transcriptie wordt bovendien het beste gemaakt door iemand die het betrokken dialect zelf spreekt. Naarmate de tijd vordert, wordt het transcriberen moeilijker: niet alleen wordt het zeer ouderwetse dialect niet goed meer begrepen door jonge mensen, maar ook zijn vele gespreksonderwerpen (bijv. de manier waarop vlas gezwingeld werd) volkomen vreemd geworden voor de moderne mens.
Het is dus nu of nooit om de opnames te transcriberen. We werken daarvoor samen met jobstudenten, maar hun kennis van het dialect en van de gespreksonderwerpen blijkt soms onvoldoende. Daarom schakelen we ook de hulp in van een heleboel vrijwilligers. Dat zijn meestal gepensioneerde mensen met een hart voor taal en een goede kennis van het dialect uit de eigen streek. Zij kijken de studententranscripties na en ze proberen de gaten aan te vullen waar mogelijk. Op dit moment zijn er dankzij jobstudente en vrijwilligers al meer dan 300 digitale transcripties beschikbaar op Dialectloket. Onze wens voor de toekomst is dat alle opnames uit de collectie Stemmen uit het Verleden een digitale transcriptie zullen krijgen zodat de inhoud van de opnames ook in de toekomst toegankelijk blijft voor mensen die geen dialect meer kennen.
Meer info over het GCND: www.gcnd.ugent.be
4. Dankbetuigingen
We zijn allereerst de UGent dankbaar voor het verstekken van de financiële middelen waarmee de digitalisering van de bandenverzameling mogelijk werd gemaakt. Daarnaast gaat onze dank ook uit naar de Vlaamse Gemeenschap en de provinciebesturen van West-Vlaanderen, Oost-Vlaanderen en Limburg, die financiële steun hebben gegeven voor het aanvullen van de database (o.a. met korte inhouden en gestandaardiseerde trefwoorden). Het Bijzonder Onderzoeksfonds (BOF) willen bedanken voor de financiële steun waardoor we digitale transcripties hebben kunnen toevoegen als een soort van ondertiteling. Liesbet Triest, Melissa Farasyn, Lien Hellebaut en Veronique De Tier hebben het project uitgevoerd.
Een en ander kon echter maar tot een goed einde gebracht worden door de hulp van vrijwilligers, die we zeer erkentelijk zijn: Anne-Marie Beirens, Hedwig Belien, Roelof Boddaert, Freddy Colson, Roos Coppens, Pieter De Dier, Leendert De Jonge, Paul De Man, Annemie Hillewaere, Myriam Lammertyn, Gudrun Van Landeghem, Luut Leroy, Dirk Raes, Jean-Marie Schepens, Jeannick Steleman, Lopke Van Acker, Ugo Verbeke, Silvia Weusten, Erfgoedcel TERF, Erfgoedbank Land van Rode.
Referenties
Rensink, W.G. (1962), Dialecten op de band. In: Taal en Tongval 14. pp. 184-196.
Vanacker, V. en G. De Schutter (1967), Zuidnederlandse dialekten op de band. In: Taal en Tongval 19. pp. 35-51.
[1] De tekst is voor een belangrijk deel gebaseerd op Vanacker en De Schutter 1967.
[2] In de Reeks Nederlandse Dialectatlassen (RNDA) zijn dezelfde 141 zinnetjes in het dialect vertaald en fonetisch genoteerd voor 1.956 plaatsen in het Nederlandse en Friese taalgebied. Het is een project dat aan de UGent gestart is door de dialectoloog E. Blancquaert; de afronding ervan duurde een halve eeuw.
[3] Nu Fonds voor Wetenschappelijk Onderzoek – Vlaanderen.
[4] De allereerste opname had plaats in het dorp Dikkebus in 1961.
[5] Er werd met snelheid 19 opgenomen met een REVOX-toestel op BASF-banden, type LGS 35 op spoelen van 18 cm diameter (zie Vanacker en De Schutter 1967:38).